Cuando uno piensa en hacer pruebas de performance en integración continua tiene que cambiar la forma de ver las pruebas como lo hacemos típicamente. Por lo general uno busca simular la carga esperada, intentando que toda la prueba sea lo más parecido a lo que será en producción, pero esto no es tan factible en un enfoque CI/CD. La diferencia más importante tal vez es el objetivo de las pruebas: en lugar de verificar cómo se va a comportar el sistema cuando esté en producción, lo que buscaremos será detectar una degradación lo antes posible. En este post voy a compartir un mecanismo para CI/CD donde se pueden detectar inmediatamente las degradaciones en performance. Esto se logra gracias a ejecutar todos los días ciertos chequeos repetitivos, buscando degradaciones en distintos sentidos. Esta metodología la aprendí trabajando para Shutterfly, ya hace dos años.
Parte de esto ya lo publicamos hace un tiempo en este post en el blog de Abstracta (en inglés), y le hicimos una entrevista a la que en ese momento era mi team leader, Melissa Chawla.
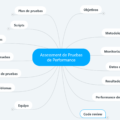
Objetivo de las pruebas
Típicamente en una prueba de performance uno simula la carga esperada del sistema en un entorno similar al de producción. Este enfoque que voy a presentar acá no sustituye ese enfoque, sino que lo complementa. Es más, con este enfoque lograremos llegar más tranquilos a la simulación de carga, evitando la necesidad de tener que aplicar grandes cambios para solucionar (o, dicho de otra forma, de encontrar grandes problemas).
El objetivo es conocer qué tanto impacto tiene cada cambio en el código en la performance del sistema, y si el impacto es negativo, descubrirlo lo antes posible, ya que de esa forma será más fácil de resolver.
¿Cómo se logra?
La forma de hacerlo es ejecutando ciertos test de carga en el pipeline, en nuestra herramienta de Continuous Integration. Esto se puede hacer cada vez que hace el build, o si vemos que toma mucho tiempo, fijar ciertos horarios frecuentes.
Lo que se vuelve crítico en este enfoque es lo siguiente:
- ¿Qué casos de prueba automatizar? Tienen que ser simples de mantener (en el caso de Shutterfly, esto estaba hecho a nivel de servicios REST, y no a nivel de flujos de usuario en la web).
- ¿Cuál es la carga a ejecutar y cuáles son las assertions que vamos a agregar en los tests? En esto me quiero centrar a continuación.
Todo esto hay que pensarlo para lograr el objetivo, para lograr detectar degradaciones fácilmente, y lo antes posible.
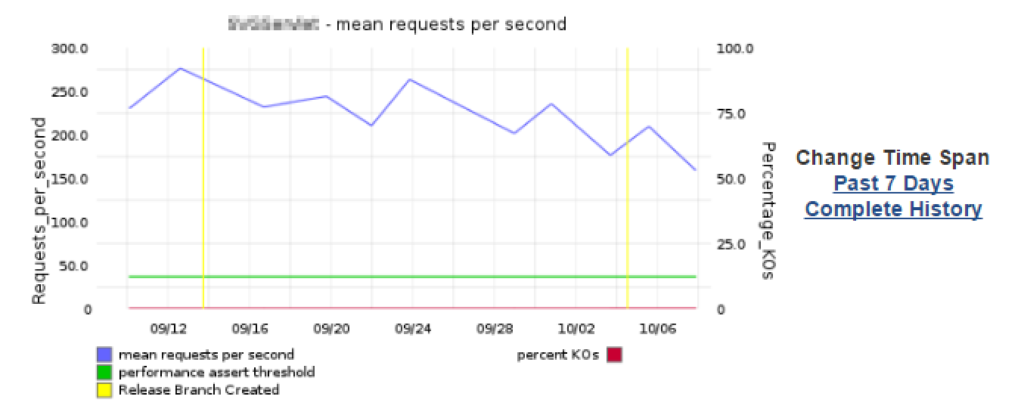
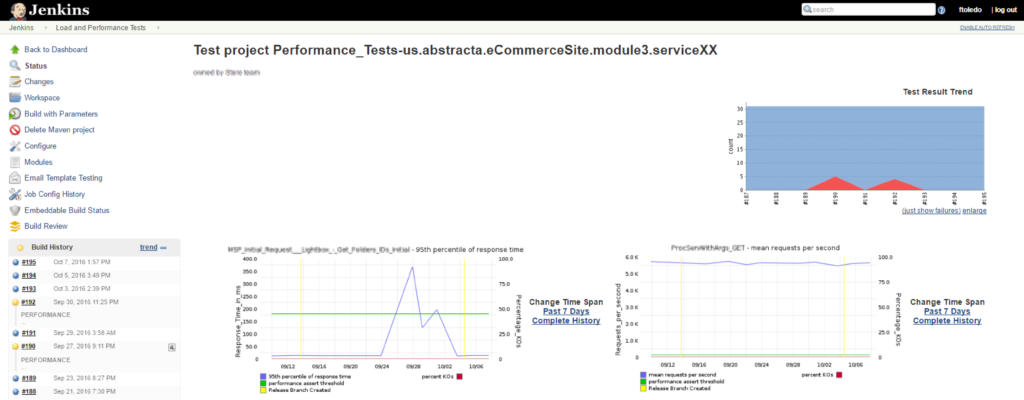
En este sentido, la estrategia es ejecutar algo con las assertions lo más ajustadas posible, como para que al degradarse, que se genere una alerta. Por ejemplo, en la siguiente imagen se ve que el servicio se degrada, pero el test sigue pasando, ya que el assertion es muy flexible (ver la línea verde en comparación a los datos en rojo).
Definir las Assertions Correspondientes
Para garantizar el éxito de este enfoque, deberíamos tener en cuenta las siguientes consideraciones:
- Entorno exclusivo, como para asegurarse que los tests son repetibles.
- Ejecutar el test con distintas cargas, como para determinar cuál es el punto de quiebre del servicio que se está probando, en la infraestructura de pruebas.
- Medir porcentaje de errores, tiempos de respuesta y requests por segundo que son atendidos.
- Definir la prueba con la carga que está un 5 o 10% abajo del punto de quiebre, donde las assertions sean las siguientes:
- respuestas con error < 1%
- tiempos de respuesta < tiempo de respuesta en punto de quiebre + 10%
- requests por segundo > requests por segundo en punto de quiebre – 10%
Yo esto lo veo como que el test pone el sistema al borde de un precipicio. Si se llega a degradar, se cae y entonces lo vamos a notar fácilmente. Por esto es interesante tenerlo al límite, porque si anda un poco peor que lo que anda hoy, entonces se va a caer.
Algunos comentarios:
- En este caso conviene que la infraestructura de pruebas sea menor que la de producción, ya que será más fácil llegar al punto de quiebre. De otra forma, (al menos en el caso de Shutterfly) para llegar al punto de quiebre se requeriría una infraestructura de test muy grande (muchas máquinas generando carga).
- Para encontrar el punto de quiebre será necesario ejecutar varias pruebas, donde se vaya observando que al aumentar la cantidad de usuarios concurrentes, sigue aumentando la cantidad de requests por segundo. En el momento en que los requests por segundo se mantienen igual o bajan, indica que algo se saturó, o sea, no está escalando, ya que llegamos a su punto de quiebre. Esto sería encontrar “la rodilla”, como se le suele llamar. Se puede observar en la siguiente gráfica:
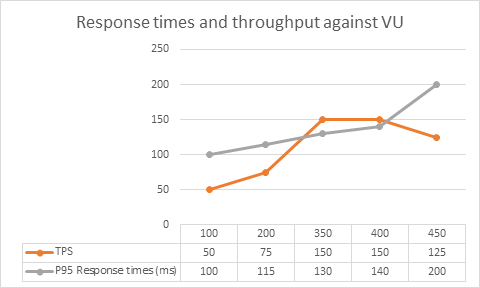
Después de configurar los assertions y la carga, es deseable revisar el test en los siguientes días, para ver si sigue comportándose estable, o si hay algo que ajustar.
Preparando el Pipeline
El pipeline ya armado se veía (en el proyecto que les nombraba) de la siguiente forma:
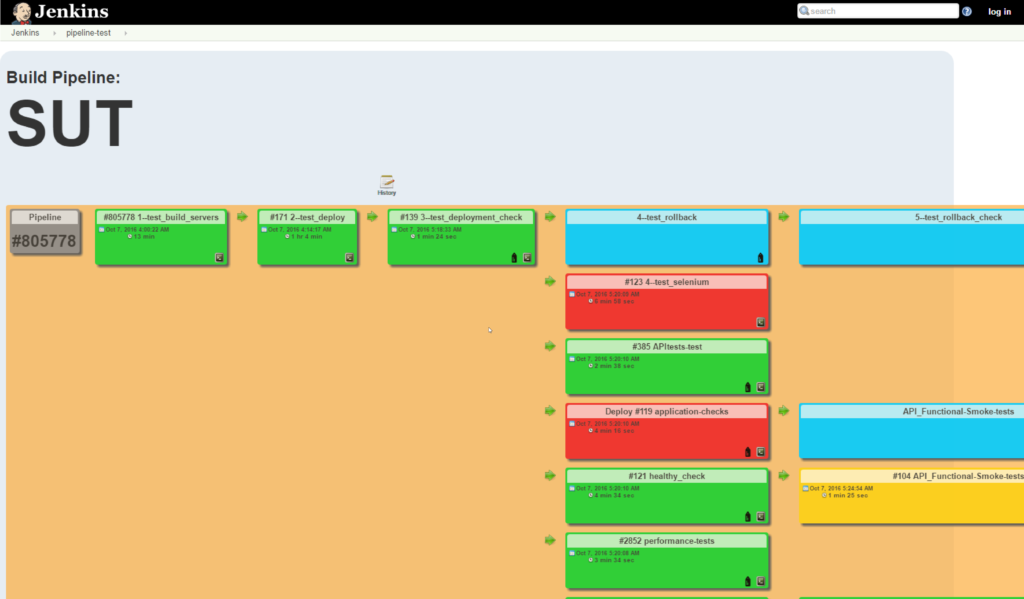
Los beneficios de esto son los típicos de CI/CD:
- Se obtiene feedback temprano.
- Vamos a tener más confianza en el build.
- Vamos a aprender sobre las cosas que hacen fallar a nuestro software a tiempo, como para evitar que esa práctica se propague a otras áreas de la aplicación.
Luego la lista de tareas se podía ver por su status:
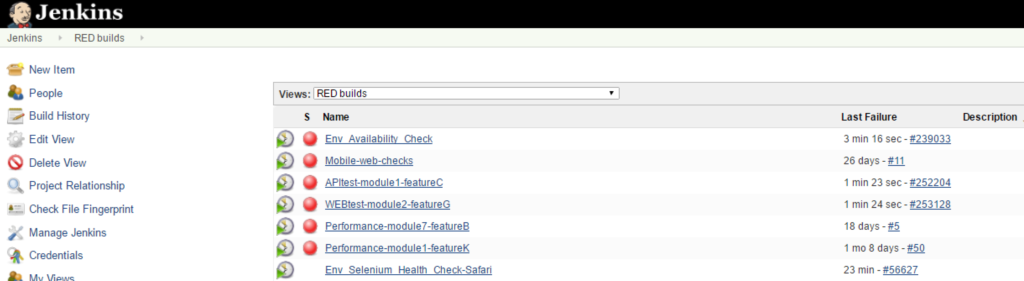
Quizá al inicio sea un poco difícil de configurar y lleva bastante trabajo de mantenimiento, ir revisando el estado de cada build, si los fallos son realmente fallos o son problemas del entorno de pruebas, etc. También será importante involucrar a los desarrolladores en estas actividades, por qué no, incluir esto en el Definition of Done.
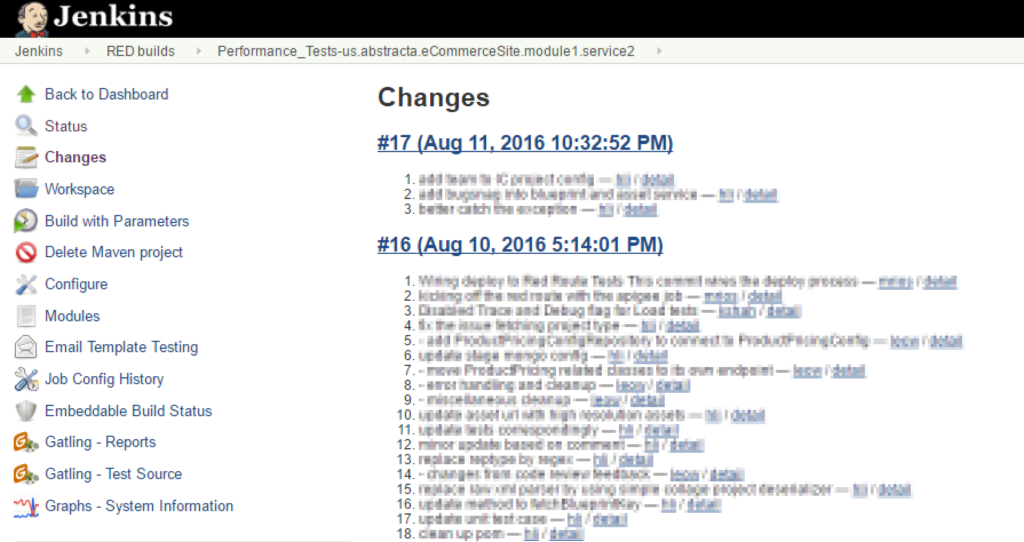
Otra cosa buena, es que como cada build tiene registro de los cambios que se hicieron, es fácil determinar qué cosas generaron el impacto observado.
En Jenkins nos irá quedando un historial de la tendencia de distintas métricas de performance para cada servicio, cuántas veces fallaron, cuándo y por qué.
Monitorización Asociada
Otra cosa importante es poder tener la monitorización de los servidores en algún sistema como ELK o Graphana, donde se vaya almancenando todo el histórico y uno pueda correlacionar la hora de ejecución del test con los datos de monitorización almacenados. En este sentido, un APM como New Relic o Dynatrace nos es de gran valor.
Conclusión
¿Cuál es el resultado de todo esto? El día que alguien ingresa un cambio que haga que el sistema funcione un 10% peor, lo vamos a saber inmediatamente. Esta es la belleza de continuous integration. Además, no tenemos la excusa de que necesitamos un ambiente de testing similar a producción. Si hoy en producción anda bien, entonces el sistema lo podemos considerar aceptable y tomar una foto en cualquier infraestructura, considerando que eso es el baseline. Claro que de esta forma habrán problemas que no se van a expresar hasta estar en una infraestructura como la de producción, con una carga como a la que va a estar expuesto, y por eso insisto, esto es complementario. Lo bueno, es que es un enfoque que es más barato en varios aspectos, y es factible mantenerlo ejecutando cada día (no es lo mismo con una prueba de simulación de carga).
¿Has tenido alguna experiencia similar?

Es una buena performance de ver como se realizan las pruebas, para simular una carga esperada , viendo que toda prueba sea lo mas parecido a lo que sera en producción, por lo tanto se logra revisar todas las imperfecciones en distinto sentido.
Lo mejor es que cada build registra los cambios que se hacen y asi determinan las fallas que generan el impacto en el software.
A parte es un enfoque que es barato en varios aspectos.
Explica claramente la importancia de las pruebas de performance, viendo que toda prueba sea lo más parecido a lo que será en producción.
Este artículo está muy bien detallado, me ayudó para adentrarme un poco más a este concepto de Pruebas de Performance y su importancia.
lo interesante es aprender a encontrar las fallas del software rapidamente, como se detalla todo en el articulo lo hace cada vez mas interesante para aprender mas sobre las pruebas de performance y su importancia