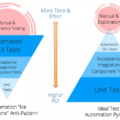
En el último viaje por San Francisco, hace un par de semanas, tuve la oportunidad de conocer a Angie Jones (experta en automatización) y visitarla las oficinas donde trabaja: en Twitter. Es impresionante lo que esa empresa invierte en sus oficinas, ¡están muy buenas! Estuvimos hablando de varios aspectos técnicos, y uno que me interesó en particular, por los últimos proyectos en los que estoy participando, es relacionado a la automatización durante el sprint. Esto es, no dejar la automatización en un track separado, con un backlog independiente, sino que considerarla como parte de las actividades para dar una User Story por terminada.

Algo que vi en el curso de Agile Developer con Matías Delgado y Santiago Ferreira, fue el enfoque de test first, al programar. O sea, si tenían que programar algo, primero automatizaban el test con Capybara a nivel de interfaz web, veían que fallaba, y luego implementaban la feature que hacía que el test funcione. Esto es fácil en este caso, ya que el mismo dev sabe qué id o nombre le va a poner a los elementos con los que interactuar (incluso se habían definido una clase especial llamada data-test, donde ponían identificadores específicos para la automatización).

Cuando esto no pasa a nivel individual, y los que automatizan son otras personas en el equipo, se debería seguir un funcionamiento similar, a nivel equipo. O sea, tener conversaciones donde se defina qué se quiere automatizar, viendo así con qué elementos se tiene que interactuar, y ahí definir identificadores para estos elementos. Entonces, el trabajo de automatización se puede hacer antes o en paralelo con el desarrollo, y lo interesante es que cuando se haga merge del código y se ejecute la prueba, la magia fluirá ?
No tengo experiencia con este enfoque de automatizar antes o en paralelo por otra persona, y si bien me parece que podría llegar a hacerse algo cercano, lo veo bastante complicado ya que dejar un test automático funcionando depende de más cosas que los identificadores. De todos modos, por más que la estrategia del equipo sea automatizar las pruebas de regresión, y eso hacerlo una vez que la feature ya está terminada y funcionando en algún ambiente, la definición de esos identificadores van a lograr que la productividad de todo el equipo aumente, no solo la de los testers.
Lo que me resultó curioso es que tanto en equipos pequeños, en empresas como Abstracta, o en empresas como Twitter, algunos de los problemas a resolver son más o menos los mismos.