Hace un poco más de un mes te comenté que comenzaríamos en Abstracta el desafío “30 días de pruebas de performance”, planteado por Ministry of Testing y PerfGuild. En este post quiero dejar un resumen de los principales aprendizajes de la experiencia, ¡que fueron muchos!

Vayamos viendo los principales aspectos de cada uno de los 30 días.
Día 1: Comprar o descargar un libro relacionado a performance testing y leerlo para el día 30
Aprovechamos los libros que trajimos de la conferencia Velocity, que estuvimos en San José este año. Son libros cortos, pero cada párrafo resume muy bien aspectos muy importantes del testing de performance. Yo leí uno llamado “Performance optimizations in a Cloud-centric world” de Andy Still. Pone foco en el hecho que al estar en plataformas Cloud uno pierde control muchas veces de las cosas que se pueden optimizar a bajo nivel, y por eso debe estar muy atento. Entre los desafíos que lista están los servicios de CDN, componentes de terceros, cómo la elección de los DNS afectan la performance y hasta los servidores o plataformas (IaaS y PaaS). También hace un repaso por las distintas herramientas de monitorización que se pueden utilizar, en particular los APM, prestándole atención a métricas como RUM o EUM (real user metric y end user metric respectivamente).

Día 2: Escuchar un podcast de performance testing
Algunos de los podcasts que escuchamos fueron:
- Uno que recomendó Joe Colantonio con Andreas Grabner de Dynatrace. Habló de shift left performance testing, de cómo ha cambiado el rol del performance tester, que ahora estamos metiendo más pruebas de performance pequeñas en Jenkins que se ejecutan en cada build. Que todo tiene que estar enfocado en el pipeline e integrar constantemente. Entonces, las pruebas tienen que ejecutar rápido. Uno no necesita una prueba de performance enorme como para encontrar problemas en la arquitectura, algoritmos, etc. ¡Hay que encontrar los problemas más temprano! Contó la idea de cómo Dynatrace (incluso la versión free) puede aprovecharse desde Jenkins.
- En este le hacen una entrevista a una tester de Songkick, y cuenta sobre las pruebas de performance que le hicieron al sitio web (cómo definieron el escenario, qué flujos automatizaron, por qué eligieron Gatling para simular la carga, etc). El podcast tiene la transcripción con la ventaja que si te perdés alguna frase lo podés leer.
Creo que más allá de los podcasts puntuales, el aprendizaje más grande que me llevé fue la costumbre de escuchar podcasts. Antes, no le había dado siquiera la oportunidad a ninguno. Ahora me agarré la rutina de tener alguno a mano para escuchar cuando tengo algún tiempo de espera, o mientras camino al trabajo.
Día 3: Encontrar 5 expertos de testing de performance para seguir en Twitter
Listo algunos perfiles que entre nosotros nos sugerimos para seguir:
Joe Calantonio, Andreas Grabner, Alex Podelko, Rebeca Clinnard, Scoot Moore, Nathan Bower, Tammy Everts, Brendan Gregg, y dejé para el final mi mayor descubrimiento: Señor Performo, quien no solo comparte aspectos relacionados a performance e incluso siguió el desafío #30daysoftesting, sino que siempre lo hace con gráficos bien interesantes y a veces con cierto humor.
En la lista de recomendados también surgieron algunos de Abstracta: David Giordano, Leticia Almeida, Fabián Baptista, Matías Reina, Sofía Palamarchuk.
Día 4: Compartir un problema de performance que hayas leído en las noticias recientemente
Algunas noticias que compartimos:
- http://www.tssznews.com/2017/06/21/sega-forever-performance-issues-reported/
- http://autoweek.com/article/vw-diesel-scandal/does-vws-diesel-fix-uk-hurt-vehicles-fuel-economy
- http://www.abc.net.au/news/2017-07-05/ato-website-breaks-down-as-people-try-to-lodge-tax-returns/8681630
Lo de HBO GO con el estreno de Game of Thrones vino después, sino le ganaba a todo lo anterior.

Día 5: Organizar una reunión con tu equipo para hablar sobre tu enfoque actual de pruebas de performance
Esto es algo que sucede a diario en Abstracta, discutimos los enfoques de pruebas de cada proyecto entre varios. Recuerdo que esa semana en particular estuvimos viendo el enfoque para un cliente en el que estamos migrando el sistema de IaaS a PaaS, y tenemos que revisar que los tiempos de respuesta y el throughput no empeoren para el mismo escenario de carga. También estuvimos conversando sobre el enfoque en otro proyecto donde los desarrolladores irán incluyendo la ejecución de las pruebas de performance dentro del ciclo de trabajo en su enfoque de CI/CD.
Día 6: Pensar sobre quiénes son los stakeholders para tus pruebas de performance
Tal como compartí acá, creo que podrían ser los usuarios, los managers, el equipo, el que paga por las pruebas, y por qué no, uno mismo.
Día 7: Refrescar tus conocimientos sobre las bases de la arquitectura de sistemas web
En lugar de volver a revisar las bases me fui a lo más actual, y algo más complejo, compartiendo lo que escribimos sobre la charla en TestingUY, donde se repasan algunos conceptos como CDN, protocolo HTTP2, etc. Les recomiendo ver el video de la charla de Leticia y Pablo.
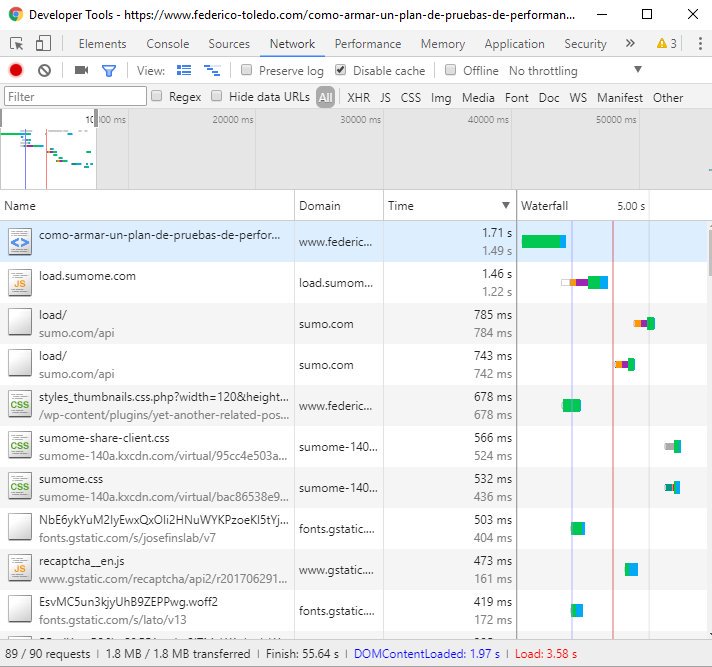
Día 8: Encontrar las 10 transacciones de API o base de datos más lentas de tu aplicación
Lo que tenía a mano para revisar era este mismo sitio, y en lugar de revisar API revisé los requests desde el browser, donde pude ver que en el top 10 solo 2 requests son a mi dominio, lo cual deja claro que la performance de un sitio web depende muchísimo de los componentes de terceros que uno agrega, a veces sin darse cuenta del impacto que están generando.
Día 9: Leer un blog de testing de performance y compartirlo con alguien
Acá hay mucha info bien interesante 🙂 https://abstracta.us/blog/
Día 10: Analizar la diferencia entre load testing y stress testing
Hace un tiempo había escrito al respecto al hablar de cómo armar un plan de pruebas de performance.
Día 11: Inspeccionar y documentar las diferencias entre tu base de datos de producción y la de testing
Esto en cada cliente/proyecto es un mundo aparte. Lo más interesante sea tal vez pensar el caso de Shutterfly, donde tanto el volumen de la base de datos como la infraestructura en el ambiente de pruebas era más reducida a propósito (generalmente los equipos de testing se quejan que sus ambientes de prueba no son iguales y que eso es un problema). El objetivo de este enfoque, entre otros, era el de poder llegar al punto de quiebre de la infraestructura con una sola máquina generadora de carga, para facilitar la prueba de performance y el análisis de los resultados.
Día 12: Diseñar una prueba de performance para tu sitio más visitado o API más usada
También, trabajo diario. El diseño de las pruebas generalmente se hace considerando no solo las más usadas, también las más críticas para el negocio o las que tienen mayores riesgos tecnológicos. El diseño implica la selección de los casos de prueba, así como los datos que se utilizarán, el modelo de carga, y las métricas a recolectar.
Día 13: Compartir una foto que muestre el uso del CPU de tus aplicaciones en producción
No tengo acceso a publicar eso. Lo compartimos regularmente entre los integrantes del equipo, de un proyecto a otro, los distintos resultados de monitorización para obtener otras opiniones, ideas, etc.
Día 14: Instalar una herramienta de testing de performance opensource, y familiarizarse con ella
Considero que aún tengo mucho para aprender de estas dos que son mis preferidas al momento:
En este mes la herramienta opensource que estuve probando y familiarizándome con ella fue GoAccess, que es útil para analizar access logs, generando un reporte muy bueno y útil para en análisis, en forma muy sencilla.
Día 15: Mirar y compartir un video de pruebas de performance
Esta fue una charla que di el año pasado en el meetup de TestingUY, comparando la ejecución de pruebas al final del proyecto de desarrollo, o realizarlo durante (o sea, ¡shift left testing!)
Día 16: Comparar y contrastar lo que es pruebas de performance y monitorización
Performance is about velocity and resource consumption, so #perftests need #monitoring to provide perf info #30daysoftesting @ministryoftest
— Federico Toledo (@fltoledo) July 16, 2017
Día 17: Pensar qué tan fácil sería para ti crear datos para una prueba de performance con 10.000 usuarios concurrentes sobre tu aplicación
En un proyecto en el que estoy preparando las pruebas ahora, se analizaron las alternativas y lo que se decidió hacer fue:
- Para una funcionalidad que crea nuevas instancias de un elemento, y recibe por parámetro un identificador, se crearon strings aleatorios para los ID que se envían desde el cliente, generándolos con una planilla de cálculo (para que cumplan determinado formato).
- Para otra funcionalidad que es una consulta de esas instancias, se generarán los datos en la base de datos con una SQL que prepararán los desarrolladores, tomando como base los datos a partir de la base de producción.
Estas dos son estrategias bastante comunes al generar datos para una prueba de carga.
Día 18: Investigar modelos de carga para pruebas de performance, y compartir los hallazgos
Con respecto a modelar una prueba de carga, yo aprendí hace más de 10 años a partir de los artículos de Scott Barber, y aún siguen siendo mis favoritos: User Experience, Not Metrics. Acá está la serie completa:
- UENM1.pdf
- UENM2.pdf
- UENM3.pdf
- UENM4.pdf
- UENM5.pdf
- UENM6.pdf
- UENM7.pdf
- UENM8.pdf
- UENM9.pdf
- UENM10.pdf
- UENM11.pdf
- UENM12.pdf
- UENM13.pdf
Día 19: Usar un sniffer o proxy para monitorear el tráfico de una aplicación web
La herramienta que más usamos nosotros es Fiddler, y en ocasiones que esa herramienta no captura el tráfico, Wireshark.
Día 20: Analizar la diferencia entre causalidad y correlación
Me encantó este artículo donde explican claramente las diferencias y la importancia de conocer esas diferencias al momento de hacer un análisis.
Día 21: Compartir tu herramienta de pruebas de performance favorita y por qué lo es
My fav #performance #testing tools are @Taurus_Test and @GatlingTool, fit well in CI/CD #shiftlefttesting #30daysoftesting @ministryoftest
— Federico Toledo (@fltoledo) July 21, 2017
Día 22: Probar una herramienta de pruebas de performance online
Mi consejo acá es BlazeMeter.
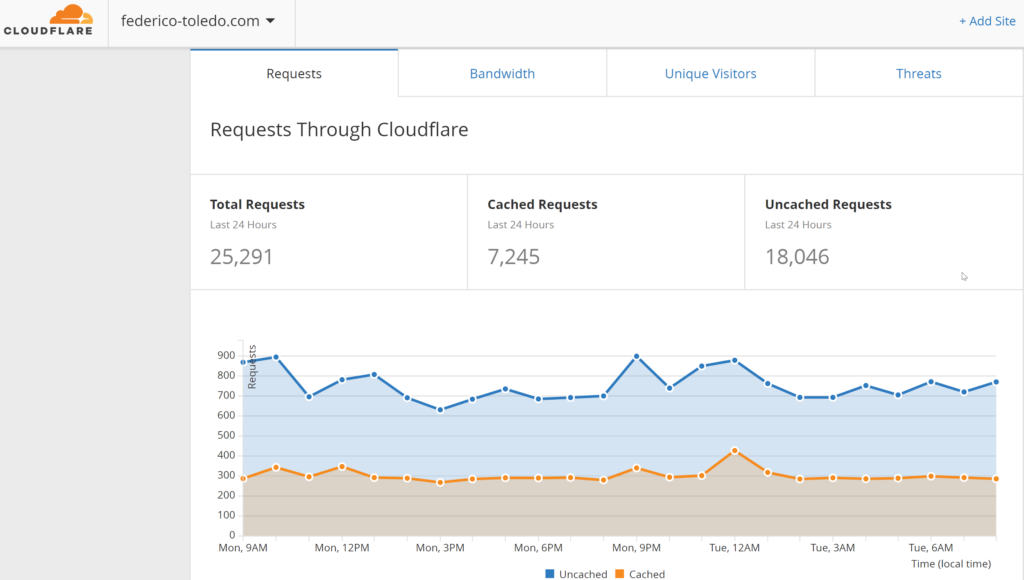
Día 23: Calcular las estadísticas básicas para tus resultados de tiempos de respuesta
Les recomiendo leer esto antes. Estuve revisando un poco las herramientas que me dejan información sobre tiempos de respuesta de este mismo sitio. Acá algunas capturas:

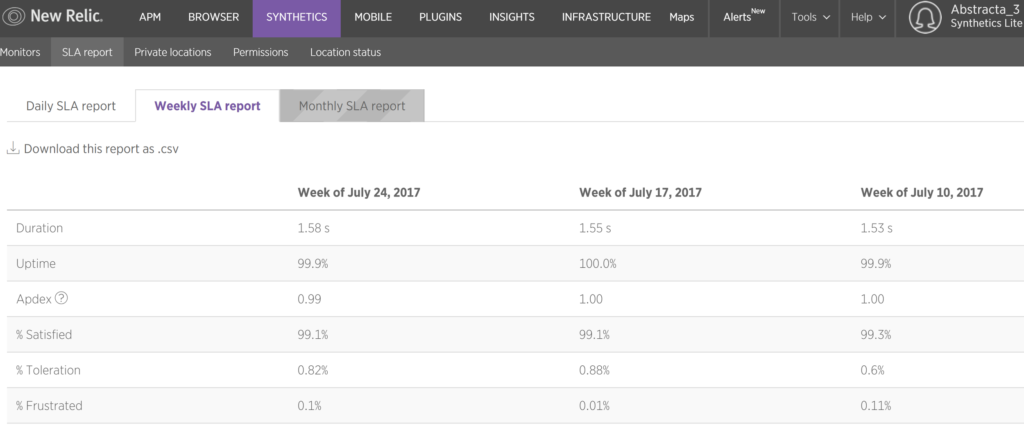
Día 24: ¿Sabes qué fue lo que causó el último pico en la performance de tu aplicación?
#day24 #30daysoftesting @ministryoftest Do you know what caused the last huge spike in your application’s performance?: @WordPress plugins!
— Federico Toledo (@fltoledo) July 24, 2017
Día 25: Compartir tres beneficios de monitorizar tu aplicación en producción
#30daysoftesting #day25 @ministryoftest 3 benefits of monitoring your app in prod:
* react with +info
* know the behavior
* prevent problems— Federico Toledo (@fltoledo) July 25, 2017
Día 26: Analizar las diferencias entre tu entorno de testing y el de producción. ¿Puede tener impacto en los tests de performance?
Sí, mientras más diferencias haya entre testing y performance entonces mayor será la incertidumbre sobre los resultados. Esto no significa que no sea válido hacer pruebas en un ambiente distinto al de producción…
Día 27: ¿Cómo compartes los resultados de las pruebas de performance con el resto del equipo?
En algunos casos reportes extensos y profundos, en otros un simple mail puntualizando algún hallazgo. Context-driven.
Día 28: Diseñar, dibujar y compartir tu dashboard ideal para performance
Según la plataforma, tecnología, requerimientos, etc., será el dashboard más útil. No hay algo ideal único. Muy de acuerdo con Sr Performo.
Dia28: I cannot get my mind into just one dashboard.Depends on a lot of factors. Cake or tacos? #30daysoftesting @ministryoftest @perfguild pic.twitter.com/w2e0XsyuW0
— Señor Performo (@Srperf) July 28, 2017
Día 29: Analizar cómo el concepto de Service Virtualization puede ayudar en las pruebas de performance
De la misma forma que ayuda en cualquier tipo de testing. Fundamental en pruebas donde no se cuenta con el control total de todos los servicios, o costaría mucho replicar el ambiente, o incluso, si se quisiera probar cómo reaccionaría nuestro sistema bajo pruebas ante distintos comportamientos del servicio que se está virtualizando.
Día 30: Compartir algún desafío relacionado a la performance que identifiques en el área de las aplicaciones móviles o en Internet de las Cosas
#30daysoftesting #day30 Challenges with perftest in the #IoT space: so many devices sending lot of data @ministryoftest @perfguild
— Federico Toledo (@fltoledo) July 30, 2017
Bonus: Revisar el programa de la conferencia online de testing de performance llamada PerfGuild
Me encanta la idea de poder acceder a una conferencia sin los costos de tiempo y tickets que implican las conferencias tradicionales. Automation Guild, ahora PerfGuild, e incluso una de QAninja en Brasil, cada vez se vuelve una alternativa más considerada.
Cerrando
Los desafíos implican siempre un aprendizaje, este fue un buen ejemplo de cómo en el equipo nos motivamos para seguir aprendiendo cosas nuevas y compartirlas entre todos.